Request a Web Runner

Go to the SlapOS web interface, and click on "New Service".
Request a Web Runner
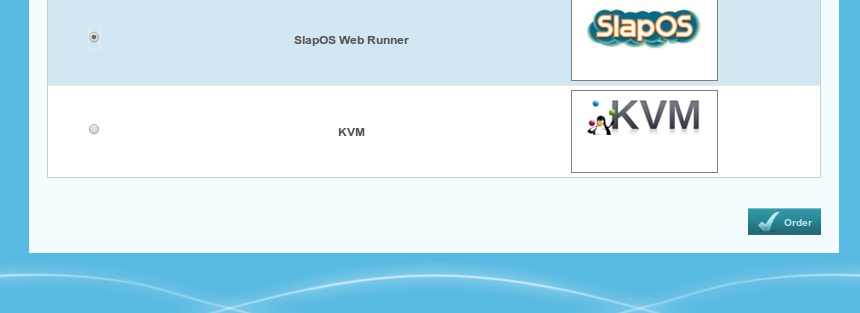
Select "SlapOS Web Runner" from the list of available software.
Choose the Web Runner version
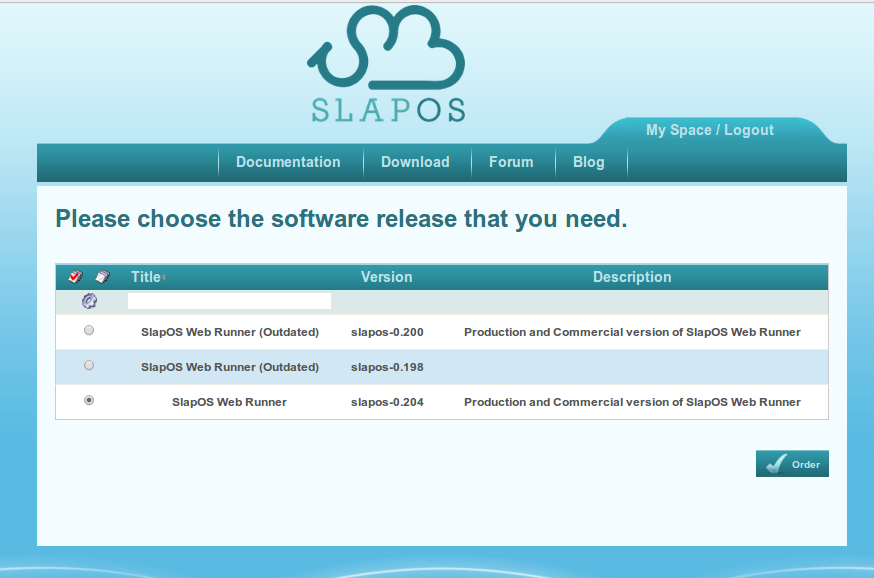
Select the latest stable release.
Assign a title to the instance
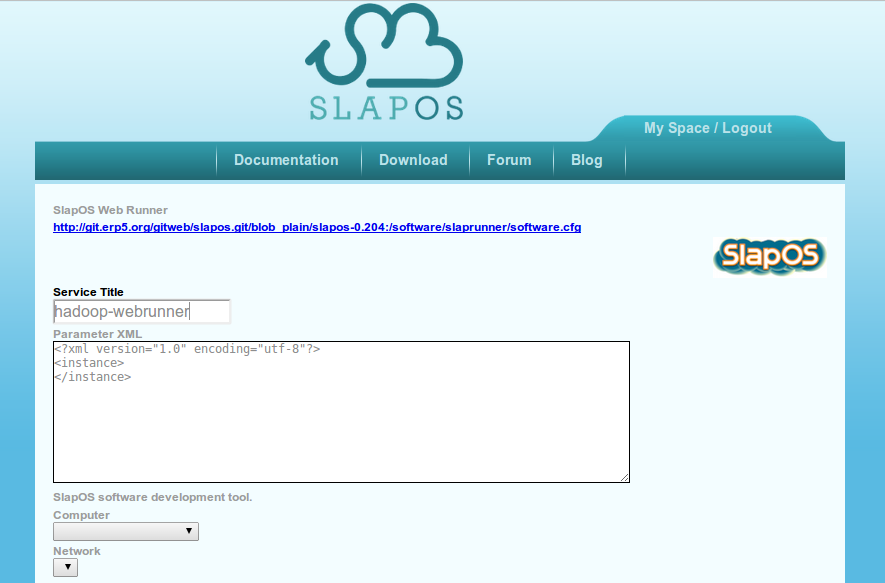
Give a meaningful title, like "hadoop-webrunner"
Request from command line
# slapos supply http://git.erp5.org/gitweb/slapos.git/blob_plain/slapos-0.204:/software/slaprunner/software.cfg COMP-xxxx
# slapos request hadoop-webrunner http://git.erp5.org/gitweb/slapos.git/blob_plain/slapos-0.204:/software/slaprunner/software.cfg --node computer_guid=COMP-xxxx
As an alternative to the previous steps, you can request the instance in the command line interface, from a slapos node.
Wait for the instance to be ready
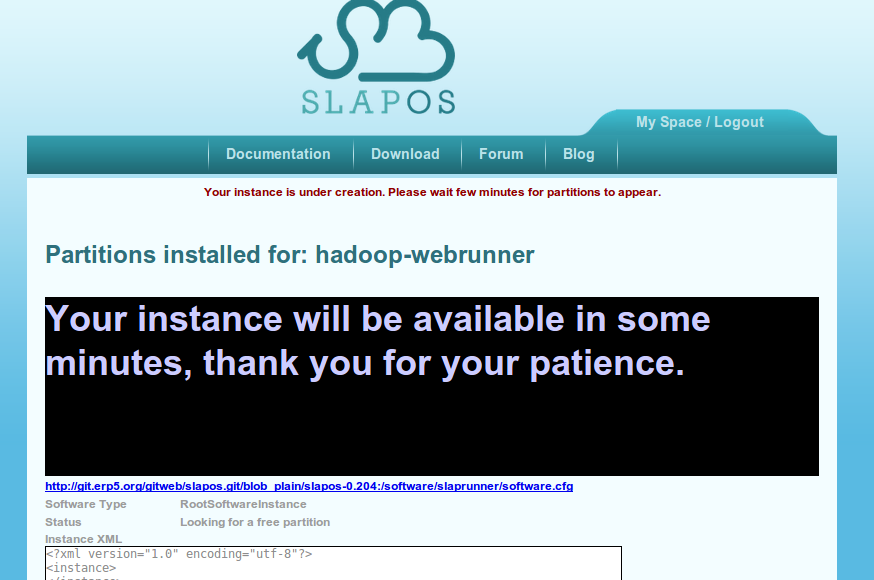
When the instance has been deployed, its page will show the login credentials.
Log in the webrunner

Check out the "hadoop" branch
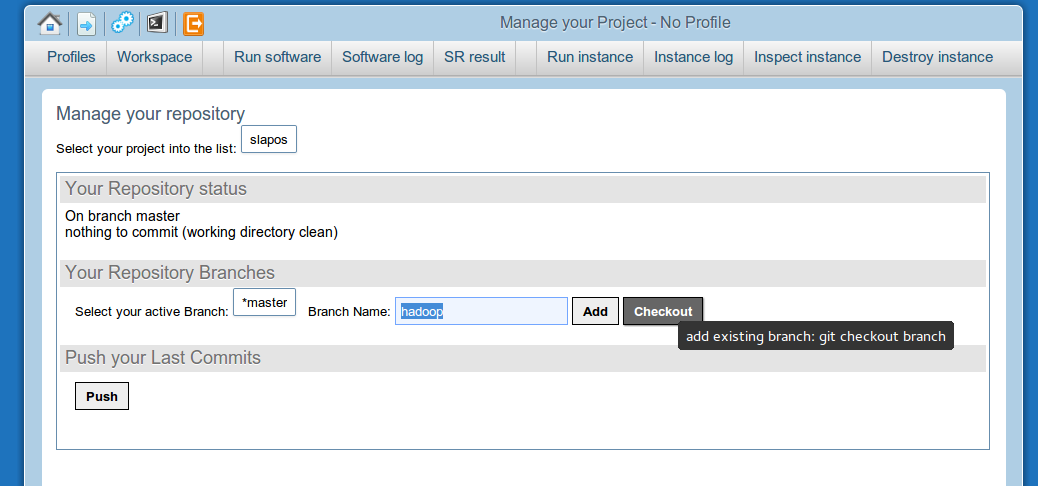
Go to Manage your repository, write "hadoop" on the branch name, and click "checkout".
Open Software Release
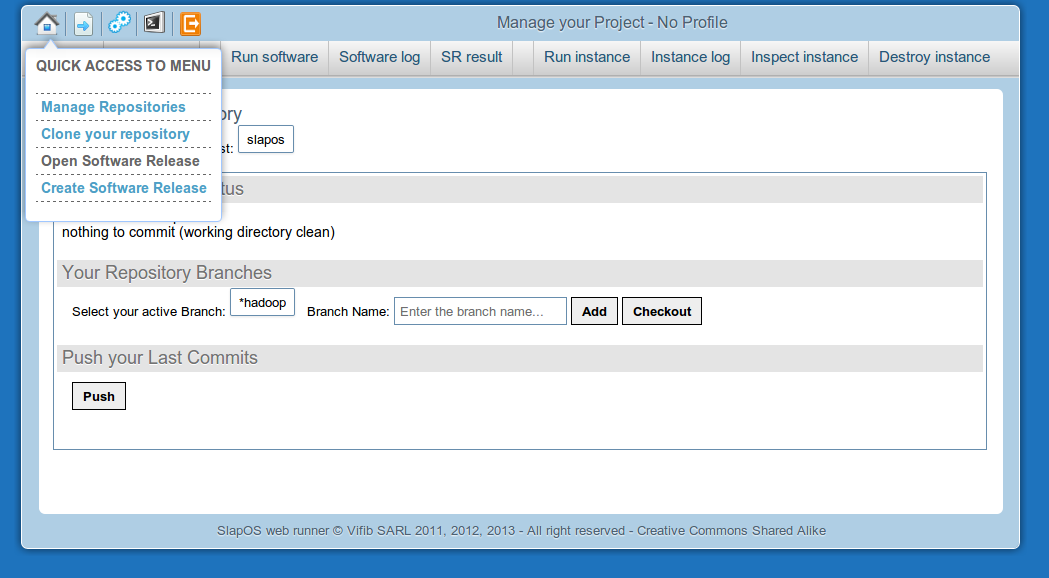
Select the hadoop-demo buildout profile
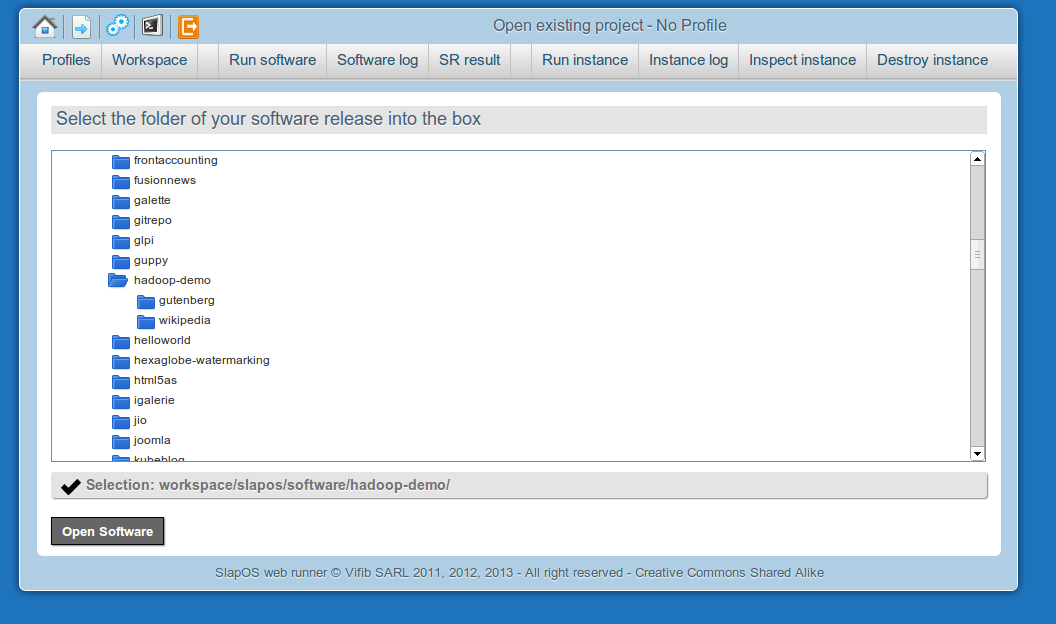
Compile with "Run software"
Deploy with "Run instance"
Log in the Web Runner shell
Click in the terminal icon on the top, and insert the shell_password that is show in the credentials page.
Run the demo
- Download raw data
- $ ./demo/gutenberg/data-download.sh
- Load data into hadoop
- $ ./demo/gutenberg/put-files.sh
- Run the job
- $ ./demo/gutenberg/run.sh
You will find the results in var/gutenberg/input, var/gutenberg/output, and var/gutenberg/raw-data.
The gutenberg demo is adapted from http://www.michael-noll.com/tutorials/writing-an-hadoop-mapreduce-program-in-python/ and performs a simple word count on text files.
A second demo is provided, which downloads a snapshot of Wikipedia and extracts the article titles.
Both are using the hadoop-streaming component, and are written in Python.
The streaming component does not use Hadoop daemons, so there is no need for a service/ directory.
If you need that, see bin/start-daemons.sh