
QR
Please scan this QR code to access the presentation from your smarphone.
Nexedi - Profile
- Largest Free Software Publisher in Europe
- Founded in 2001 in Lille (France) - 35 engineers worldwide
- Enterprise Software for mission critical applications
- Build, deploy, train and run services
- Profitable since day 1, long term organic growth
Nexedi is probably the largest Free Software publisher with more than 10 products and 15 million lines of code. Nexedi does not depend on any investor and is a profitable company since day 1.
Nexedi - Clients
Nexedi clients are mainly large companies and governments looking for scalable enterprise solutions such as ERP, CRM, DMS, data lake, big data cloud, etc.
Nexedi - Free Software Stack
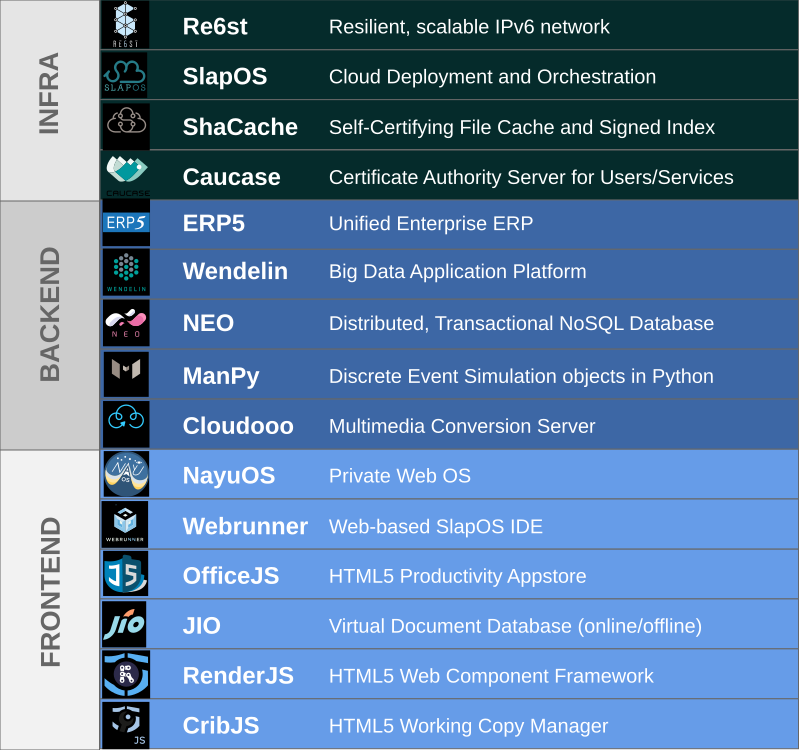
Nexedi software is primarily developed in Python, with some parts in Javascript.
Open Source / Open Hardware Meetup @Fraunhofer IAO Stuttgart
This presention was first given at Fraunhofer IAO in Stuttgart with a focus on Industry 4.0
2nd Edge Computing Forum @Fokus
It was later introduced at Edge Computing Consortium Europe in Berlin
Agenda
- History
- Design
- Success Cases
- Future
We will first introduce the history of SlapOS.
We will then focus on the key design strengths of SlapOS.
At the end we will showcase other SlapOS success cases and provide insights on the future of SlapOS.
History
SlapOS is an overlay on top of Linux or any POSIX compliant OS. It can act as a general purpose edge computing system, cloud computing or orchestration system.
SlapOS: (one of) the first edge computing systems
https://www.cio.com/article/2417512/servers/vifib-wants-you-to-host-cloud-computing-at-home.html
We've been deploying edge computing at Nexedi since around 2008 with SlapOS.
Everyone has a different notion of edge computing. We tried to define them in this article: Five Evolutions of Cloud Computing "https://www.nexedi.com/NXD-Blog.Five.Cloud.Evolution". However, Edge Computing is kind of buzzword that covers many old ideas of distributed computing that recently became more widely accepted.
IEEE Publication in 2011
SlapOS: a Multi-purpose Distributed Cloud Operating System Based on an ERP Billing Model
SlapOS ideas originate in a discussion with Professor Christophe Cérin - who is currently visting HDU - about grid computing systems and grid coordination. Cloud was very popular at that time (2009) and Nexedi had been using devops (buildout) to automate all its deployments.
It became obvious during this dicussion that the main purpose of cloud was to automate things, rather than virtualise things or put them in a datacenter. It also became obvious that nothing prevented from doing cloud in a decentralised way. IPv6 had become available in all homes in France thanks to Free. It was therefore possible to host servers at home and build a distributed cloud.
One the of key ideas that Nexedi brought was that everything is a service and that cloud automation is about automating the process of order, delivery and accounting of IT services using an ERP model, just like for e-commerce. One other company in the world had a similar idea: Baosight. Baosight also built its own cloud using an ERP model and it worked.
Sadly, the idea of distributed cloud or the idea of ERP model for cloud was not popular in 2009. Most engineers still had in mind legacy concepts from telecom industry and could not imagine that we actually do not need datacenters.
SlapOS Lecture at HDU in 2011
The first lecture about SlapOS was given at HDU with Prof. Confeng Jiang.
SlapOS Lecture at HDU in 2011
Some of the students we trained now work at Qiniu or large IT companies in China.
Why don't you use OpenStack?
We often get questions such as:
- why don't you use virtualisation?
- why don't you OpenStack?
- why don't you use Docker?
- etc.
We usually answer: because they don't work according to industrial grade standards, even now, and because they did not exist in 2008.
The meaning of "does not work" is a bit different for Nexedi and for most open source developers. In Nexedi, we want systems that "work always in the same way and for a very long time", rather than systems that "work sometimes" and are easy to install with a beautiful web site. We want this kind of predictability for everything (build, ordering, etc.). We care more about improving our software than community or documentation. If a solution works but is rejected by most community, we ignore community because we have to serve our customers first (our business model is based on customers, not on venture capital).
So, in the case of OpenStack, we believe that its architecture is not promise based and can thus never be stable. This is explained with more details in "Five Evolutions of Cloud Computing".
We also tried to use OpenStack VMs from various suppliers, including OVH, Rackspace and some governments clouds. We did some statistics on hundreds of servers. The conclusion was terrible: there are in average three times more unexpected reboots of OpenStack VMs than on a micro-server hosted in someone's home without UPS.
Another conclusion is that OVH bare metal servers are remarkably stable. Servers will reboot unexpectedly in average once a decade.
Why don't you use LXC/Docker?
- Not portable across Linux distros
- Not supported outside Linux
- Still a bit unpredictable on Linux
~ $ free -h
https://www.nexedi.com/NXD-Blog.Docker.SlapOS.Nano.Container.Elbe
The article "Are Linux containers stable enough for production and why Nexedi uses SlapOS nano-containers instead ?" (https://www.nexedi.com/NXD-Blog.Docker.SlapOS.Nano.Container.Elbe) explains for example why we do not use Docker or LXC containers and why we do not plan to use them for ourselves. Until recently, it was very difficult to find anyone who would agree with us (just like OpenStack 10 years ago). But more and more people now understand the problems of binary portability with Linux kernel and its consequence on Docker/LXC containers.
So, we might use "kernel namespaces" with SlapOS.
SlapOS could easily support docker/LXC type containers; we actually already implemented it. But those docker/LXC containers will only work if some strict conditions are met: host OS/Kernel and guest OS/Kernel should be same for example. Sadly most developers do not understand those conditions and do not respect them. It is thus difficult to provide something that works according to our standards
Design
Let us now review SlapOS architecture and design goals.
Everything is a Service
- A database service
- A kvm service
- A routing service
- An HTTP cache service
- An ERP cache service
- etc.
In Unix, everything is a file.
In SlapOS, everything is service.
A database is service. A qemu runtime is a service. A routing daemon is a service. An HTTP cache is a service. An ERP is a service.
Every service has a URL that defined how to communicate with it.
Multiple services communicating together can be assembled as a complex service.
SlapOS: Service Operation Automation
~ $ slapos request mariadb my_db
~ $ slapos request kvm my_vm
~ $ slapos request re6st-registry my_registry
~ $ slapos request cdn my_cdn
~ $ slapos request erp5 my_erp
Therefore, in SlapOS, there is no difference between IaaS, SaaS, PaaS, NaaS or any XaaS.
It is just about requesting X as a service by calling slapos request.
Design Goals: Unify Service Description
- no matter where
- no matter when
- no matter what
- no matter which distro or OS (POSIX)
- no matter which version of distro
- no matter which architecture
- no matter complexity
- with real time, high peformance and resiliency support
- and at lowest possible cost
What mattered to Nexedi when SlapOS was created is that whatever service we would deploy, we wanted to be able to deploy it fully automatically using the same "service descriptor language", no matter:
- where (data centre, on premise, inside an airplane, on a smartphone, inside a sensor, etc.);
- when (today, in 5 years, in 10 years, etc.);
- what (database service, VM service, application sever service, smart sensor processing service, data buffering service, etc.);
- which distro (Debian, Ubuntu, Fedora, CentOS, FreeBSD, SuSE, RedHat, Arch, etc.);
- which version of distro (2016, 2017, 2018, etc.);
- which architecture (bare metal, VM, x86, ARM, etc.);
- complexity (unitary service, orchestration of dozens services);
- real time constraints (no constraint, hard real time).
Service Unification from Edge to Space
Ideally, SlapOS should deploy on smartphones, 5G gNodeB, central servers, drones, satellites, etc. using the same unified service description approach.
SlapOS was actually deployed some years ago inside a 777 flight of JAL between Paris and Tokyo, serving real time web content during the journey.
Design Goals: Automate Service Lifecycle
- catalog (of services)
- build
- test
- ordering
- provisioning
- configuration
- orchestration
- monitoring
- issue tracking
- accounting
- billing
- disaster recovery
We wanted our solution to cover all aspects of the lifecycle of service:
- catalog of available services (appstore);
- build;
- ordering;
- provisioning;
- configuration;
- orchestration;
- monitoring;
- issue tracking;
- accounting;
- billing;
- disaster recovery (incl. ability to rebuild everything after 10 years):
Design Goals: Security and Resiliency
- insecure network
- unstable network
- unstable hardware
- unstable electricity
- vanishing code sources
And we wanted our solution to be take into account "real world" features of public infrastructures which we had observed and made statistics of:
- insecure network (anyone can spy it);
- unstable network (packets are lost, connectivity is lost);
- unstable hardware (any component can crash);
- unstable electricity (electricity shortage is always possible).
The article "Downtime statistics of current cloud solutions" (http://iwgcr.org/wp-content/uploads/2013/06/IWGCR-Paris.Ranking-003.2-en.pdf) should give a good overview of the lack of resiliency of cloud, networking and electricity no matter who is the supplier.
Promise Based Minimalist Architecture
- Master: ERP5 (promise definition, ordering, provisioning, accounting, billing, issue tracking)
- Slave: buildout (promise execution, build, instantiation, configuration, monitoring)
So, we used buildout (http://docs.buildout.org/en/latest/) as the base for our service descriptor language and ERP5 to keep track of "service lifecycle" after we found out that any edge or cloud system can be made of two components: a devops and an ERP (see "SlapOS: SlapOS: A Multi-Purpose Distributed Cloud Operating System Based on an ERP Billing Model" https://ieeexplore.ieee.org/document/6009348).
For resiliency, we based all our design on the idea that resiliency must be implemented with software and should rely on redundant infrastructure on redundant sites with redundant suppliers. However each site or hardware does not need to be redundant.
This approach was quite successful. By sticking to a very simple and minimal architecture, we could achieve with a small budget what huge community projects such as OpenStack still fail to achieve after 10 years. And we could do much more, because our architecture was more generic.
Advanced Features
- Recursivity: SlapOS Master can provision a SlapOS Master on a SlapOS Node
- Federation; SlapOS Master can delegate provisioning to another SlapOS Master
- Zero Knowledge: no secrets on SlapOS Master
SlapOS provides advanced features of a modern cloud and edge operation system.
With recursivity, SlapOS can deploy itself. It also means that SlapOS can test itself.
With federation, one SlapOS system can support services of another SlapOS system. For example one SlapOS system can delegate CDN to another SlapOS system that is able to supply it.
The idea of Zero Knowledge consists of ensuring that no secrets are shared in SlapOS master. It could also mean that SlapOS node provide no remote ssh.
Nano Containers
- declarative
- bare metal
- multiple versions
- multiple instances
- no superuser needed
- portable across Linux distributions (unlike Docker)
- portable to other POSIX OS (Android, FreeBSD, etc.)
- (option) source cache (encouraged)
- (option) binary cache
- (option) virtualisation
- (option) name spaces
- (option) containerisation (discouraged)
Nano containers in SlapOS simply means that SlapOS uses the standard POSIX isolation of unpriviledged users.
Thanks to buildout technology, it is declarative and runs on bare metal.
Multiple versions of the same software can be deployed at the same time on the same host. Multiple instances too.
All services are meant to run as a normal user (unpriviledged). We run nothing as root except the core SlapOS daemon (slapgrid). We patched any libraries that could not execute without root privileges (postfix) or hardcoded some path (ex. X11).
Thanks to buildout, SlapOS is portable across Linux distributions or even to other POSIX systems such as Android, FreeBSD, MacOS. It is just a matter of extending the buildout profile to take into account specific compilation options for each platform.
Source code can be cached to ensure that it can be rebuilt after ten years.
Binaries can be cached (and shared) to accelerate installation.
SlapOS can run inside or outside a virtual machine. It can deploy virtual machines too.
It can support namespaces or cgroups if necessary.
It can even deploy LXC/Docker type containers but this is something we discouraged for reasons explained previously.
re6st
re6st was created to fix problems of current Internet through an IPv6 overlay network.
In today's Internet, latency is usually sub-optimal and telecommunication providers provide unreliable transit. There are lots of network cuts. DPI systems introduce sometimes data corruption in basic protocols (ex. TCP). Governments add censorship and bogus routing policies, in China for example. There is no way to ensure that two points A and B on the Internet can actually interconnect. The probability of connectivity fault is about 1% in Europe/USA and 10% inside China. It is too much for industrial applications.
Without re6st, SlapOS (or any distributed container system) can not work. If one has to deploy 100 orchestrated services over a network of edge nodes with a 1% probability of faulty routes, the overall probability of failure quickly becomes too close to 100%. There is therefore no way to deploy edge without fixing the Internet first.
This is very easy to understand in China. But it is also true in Europe and USA (maybe not yet in Japan).
re6st routing provides one solution to that. re6st is available in China (license: 中华人民共和国增值电信业务经营许可证:沪A1-20140091). Nexedi has the right to provide global low latency high resiliency IPv6 network for IoT.
In addition to re6st, we use buffering to that we do not lose data sent by edge nodes (gateways or sensors) in case of application server failure for example:
Both re6st and fluentd are used in all IoT deployments done by Nexedi and based on SlapOS.
Linuxboot
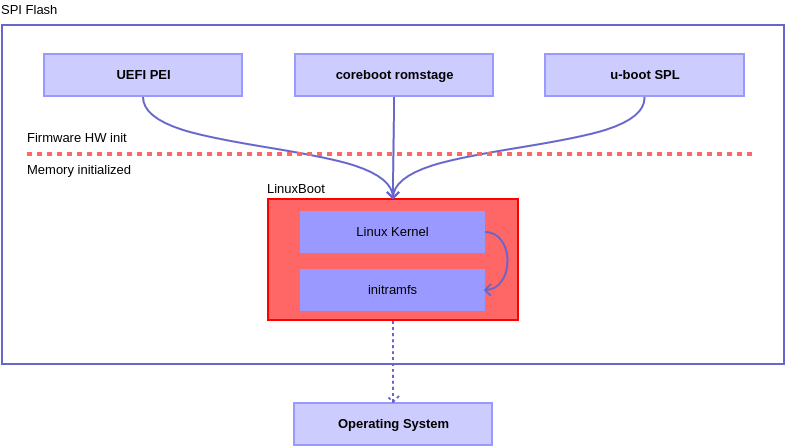
LinuxBoot is a firmware for modern servers that replaces specific firmware functionality like the UEFI DXE phase with a Linux kernel and runtime. Why? Improves boot reliability by replacing lightly-tested firmware drivers with hardened Linux drivers. Improves boot time by removing unnecessary code. Typically makes boot 20 times faster. Allows customization of the initrd runtime to support site-specific needs (both device drivers as well as custom executables). Proven approach for almost 20 years in military, consumer electronics, and supercomputing systems – wherever reliability and performance are paramount.
Success Cases
Let us have a look at some success cases that use SlapOS.
Success Case: WebRunner IDE
SlapOS "Web Runner" is a Web based IDE. It is used in Nexedi to develop all projects for its customers. Nexedi runs thousands of Web Runners on its global infrastructures. Developers only need a Web Browser and a single "slapos request" to get their development environment, which is now automated and unified across entities.
Success Case: Teralab
https://www.nexedi.com/success/slapos-IMT-Documents.Teralab.Success.Case
Teralab runs a big data infrastructure for French government. See: https://www.nexedi.com/success/slapos-IMT-Documents.Teralab.Success.Case.
Success Case: Rapid.Space
Rapid.Space (https://rapid.space/) is a high performance, low cost cloud infrastructure that provides:
- big servers;
- CDN;
- (soon) IoT buffering.
It is available in Europe and soon in China through partner company. It is based on SlapOS and Open Compute Project (OCP) hardware, the same as the one used by Facebook.
Everything about Rapid.Space is public.
- Business Model: https://www.nexedi.com/NXD-Blog.Low.Cost.Cloud.Business.Model
- Performance Optimisation: https://www.nexedi.com/NXD-Blog.High.Performance.VM.DB
- Source Code: https://slapos.nexedi.com
Success Case: Grandenet Global CDN
HTTP2/QUIC CDN all over the world including in China (we have a license for that)
Success Case: Factory-in-a-box

Automated deployment of "smart factory box" for some automotive company in new factories located in smaller countries. All kinds of services can be remotely such as ERP, CDN, MES, etc.
Success Case: LTE/NR SDR NMS
https://www.nexedi.com/NXD-Document.Press.Release.NMS.Preview.MWC.2018
SlapOS was extended as a Network Management System (NMS) for LTE/NR networks. It deploys SDR and configures the bare metal Linux for hard real time signal processing through cgroup configuration.
Success Case: Data Collector
Woefel (Germany) collects data from hundreds of wind turbines using fluentd which is itself deployed using SlapOS (server side). An experimental extension can deploy fluentd in the sensor directly and use a GPU to process signal in real time.
Future
The future of SlapOS depends on SlapOS main users as well as on community contributions.
SlapOS Roadmap
- IDE: Jupyter-lab
- Secure Boot: ELBE RFS
- Real-time: PREEMPT_RT
- I4.0: OPC-UA PubSub
- TSN: AccessTSN, babel
SlapOS will son include support for Jupyter-lab, a secure boot based on ELBE (Linutronix).
We hope to support hard real time in sensors with PREEMPT_RT.
We hope to add support for industrial automation using OPC-UA.
We also hope to create routers based on SlapOS and including time division radio networks (Wifi, NR) for deterministic communication in the factory.
Hard Real Time Edge Computing
- Orchestration of real-time services
- Real-time orchestration
- Orchestration of IoT OS (ex. RiOT)
- Orchestration of OS-less IoT (ex. ESP32)
- Deterministic sockets
- Software defined TSN
To achieve this future, a certain number of technologies must be created. Most of them require improvements of the Linux kernel or extensions of SlapOS to non POSIX operating systems.
Orchestration or real-time services requires to model the concept of real-time resource in provisioning algorithms in relation to base system configuration.
Real-time orchestration requires to intoduce determinism in the provisioning algorithms.
Orchestration of IoT OS requires to extend SLAP protocol beyong POSIX and buildout.
Supporting OS-less IoT may require to implement the notion of digital-twin for micro-controllers in a SlapOS stack.
Derministic sockets must be used in all services that are deployed with real-time.
Software defined TSN must also be provided so that TSN can be disseminated beyond a few (expensive) suppliers or industrial automation tools.
SlapOS TSN
http://www.nexedi.com/NXD-Blog.Free.Software.I40.Automation.OPC-UA.TSN
A first reference architecture has been designed. A collection of reference software has been prepared. We are now looking for factories willing to deploy their factory automation using SlapOS for aspects such as virtual-PLC, virtual robot controller and determenistic radio networking.
References
- https://slapos.nexedi.com/ contains the documentation and tutorials, especially some architecture introduction
- https://www.ctocio.com/tech/computing/16071.html explains how SlapOS solves problems similar to those solved by Plan9 but using "services" rather than "files".
You can find more articles related to SlapOS:
- https://slapos.nexedi.com/ contains the documentation and tutorials, especially some architecture introduction
- https://www.ctocio.com/tech/computing/16071.html explains how SlapOS solves problems similar to those solved by Plan9 but using "services" rather than "files".
- https://www.cio.com/article/2417512/servers/vifib-wants-you-to-host-cloud-computing-at-home.html was the first press article when we started to deploy "cloud servers at home" which can be considered as one type of edge computing
Thank You
- Nexedi SA
- 147 Rue du Ballon
- 59110 La Madeleine
- France
- +33629024425
For more information, please contact Jean-Paul, CEO of Nexedi (+33 629 02 44 25).