
QR
This presentation can be shared using the QR displayed above.
Agenda
- Nexedi
- Rapid.Space
- Hardware
- Low Cost Architecture
- Software: SlapOS
- SlapOS Design
- SlapOS Success Cases
- Future
We will first introduce Nexedi. Then we will explain what is Rapid.Space and the two problems that we had to solve.
We will then look in details in to hardware problems.
We will explain then how we could kill costs.
We will focus in the last part on software. First, on the reasons why we use SlapOS. Then on the key design strengths of SlapOS.
At the end we will showcase other SlapOS success cases and provide insights on the future of SlapOS and Rapid.Space.
Nexedi - Profile
- Largest Free Software Publisher in Europe
- Founded in 2001 in Lille (France) - 35 engineers worldwide
- Enterprise Software for mission critical applications
- Build, deploy, train and run services
- Profitable since day 1, long term organic growth
Nexedi is probably the largest Free Software publisher with more than 10 products and 15 million lines of code. Nexedi does not depend on any investor and is a profitable company since day 1.
Nexedi - Clients
Nexedi clients are mainly large companies and governments looking for scalable enterprise solutions such as ERP, CRM, DMS, data lake, big data cloud, etc.
Nexedi - Free Software Stack
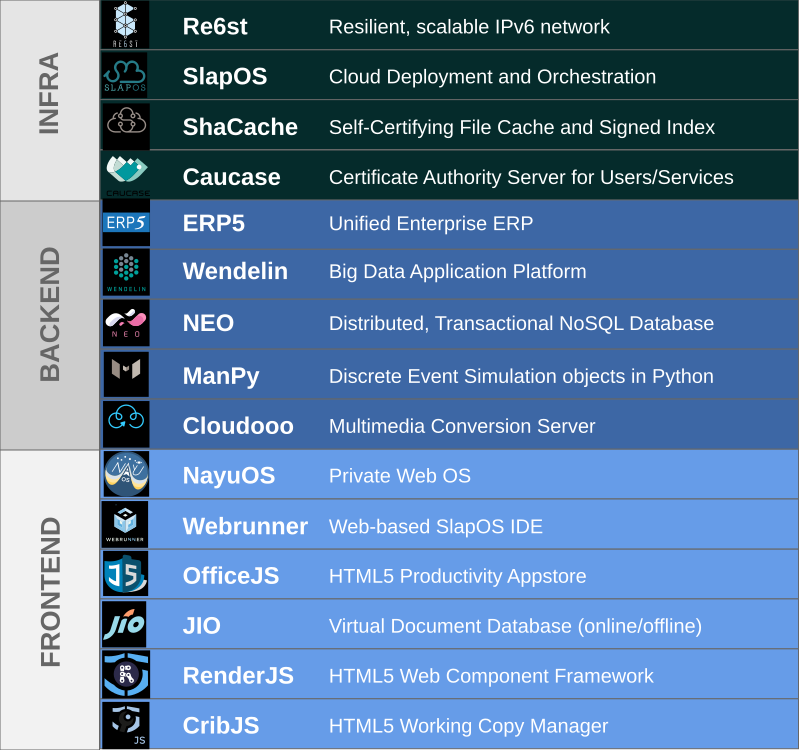
Nexedi software is primarily developed in Python, with some parts in Javascript.
Rapid.Space
Let us now have a look into Rapid.Space
Rapid.Space
Rapid.Space (https://rapid.space/) is a high performance, low cost cloud infrastructure that provides:
- big servers;
- CDN;
- (soon) IoT buffering.
It is available in Europe and soon in China through partner company. It is based on SlapOS and Open Compute Project (OCP) hardware, the same as the one used by Facebook.
Everything about Rapid.Space is public.
- Business Model: https://www.nexedi.com/NXD-Blog.Low.Cost.Cloud.Business.Model
- Performance Optimisation: https://www.nexedi.com/NXD-Blog.High.Performance.VM.DB
- Source Code: https://slapos.nexedi.com
Hardware Platform
This is how Rapid.Space hardware platform looks like. You can see on the picture an OCP rack inside Data4 data centre.
Software Platform
This is how Rapid.Space hardware platform looks like. It is mainly a console to order and monitor Rapid.Space services such as virtual machines or CDN.
Hardware
Let us now go into the details of the hardware platform and its costs.
Space
483€ / month / rack or 13€ / month / server
First we need a data centre. We use Data4, a data centre that is also use by very famous public clouds. It is located in the south of Paris. Hosting one rack costs about 483€ per month. This is not so cheap actually because Data4 is high end.
We could probably reduce this cost by using a free air flow, low cost, data centre. OCP hardware can handle up to 35 degrees. This means that by hosting servers in northern Europe or northern China, no air cooling is needed, which saves both investment costs and operation costs.
Space
The floor of the data centre has to be made of concrete with vinyl painting. Concrete must be strong enough to handle 2 tons per square meter.
Space
All cables should be on top of the OCP rack. This is cheaper and more convenient. Electricity and network should be placed in different path. Electricity equipment can be places next to walls.
Electricity

0.13€ / kWh or 26€ / month / server
We should now consider the cost of electricity. In France, it is 0.13€ per kWh. This is the cost with all electricity conditioning of the data centre. This cost could be much lower in China where government has set special pricing based on environmental goals.
Network

1500€ / month / 10 Gbps
250€ / month / 1 Gbps or 8€ / month / server
The next cost is Internet transit. With companies such as Cogent, 1 Gbps can be as cheap as 150€ per month, which is enough to be shared by one rack of servers.
OCP Server

2500€ / server
60€ / server / month
Server itself costs about 2500€ fully equipped (256 GB RAM, 4 TB SSD, 40 vcores). This price is possible by using re-certified hardware. The hardware is based on OCP standard, the same standard as the one Facebook is using. We use Splitted Desktop (SDS) as our supplier. We actually launched Rapid.Space to also help SDS showcase their technology, since OCP only makes sense economically if one purchases a complete rack (it is incovenient to operate a single server).
Server
Here is how the rack looks like. It is big and heavy. It required a good logistic company to be shipped and installed. And mostly a door that is high enough.
Switch

16 x 40 Gbps - 500€
We now need a switch. Ideally, we would prefer an unmanaged switch (cheaper, safer, more stable) because all networking is software based on SlapOS. But we would find for less than 500€ a 16 port 40 Gbps managed switch (also open hardware). With the right splitting cables, this is same as a 64 port 10 Gbps switch.
Loan

Less than 5€ / month / server
Next we need a loan to purchase hardware without consuming cash. France's BPIFrance just does that for a moderate price. We consider that the monthly cost of the loan is less than 5€ per month and per server.
Broken Hardware
5€ / month / server
Next, we need to replace or repair hardware from time to time. 5€ per month per server is reasonable (this is 8% of hardware price).
Others
- Hardware management: 20€ / month / server
- Platform management: 20€ / month / server
- Web site design: 5000€ every other year
https://www.nexedi.com/NXD-Blog.Low.Cost.Cloud.Business.Model
And finally, we need to consider the cost of handle the hardware. This means going on site, checking things, installing the base operating system, monitoring it. It also means handling orders, provisioning and accounting. A total of 40€ (20 + 20) per month seams reasonable based on VIFIB's experience of decentralised cloud.
It should be possible to reduce this amount with larger infrastructure and more automation. But it is also possible to spend too much on this as it happened with France's sovereign cloud projects which wasted dozens of millions of Euros if not hundred millions of Euros trying to make their OpenStack based platform work.
Total
| Item | Amount (€) |
|---|---|
| Server amortisation | 69 |
| Financial cost of loan | 6 |
| Network | 8 |
| Electricity | 26 |
| Hosting | 13 |
| Management software | 20 |
| Hardware management | 20 |
| Hardware replacement | 4 |
| Hardware repair | 1 |
| Total expenses | 168 |
With all values we just introduced, we reach a total of 168€ per month and per server. This leaves a profit of 27€ to reach the public price of 195€, or 13%, a value that is reasonable for a capital intensive industry and that will help getting a loan from the banker.
Business Plan
All values are also available in our business plan which is public. Feel free to download it and adapt it. If you need a Free Software spreadsheet, consider using OfficeJS (https://www.officejs.com). It works everywhere in the world including in China. And since it is web based (offline Web technology), you do not need to install anything.
China Figures
| Item | Price in China (RMB) | Price in France (€) | Comment |
|---|---|---|---|
| Price of 1 Gbps (per month) | 6.500 to 20.000 | 270 | 3.5 to 20 times more expensive |
| Price of 1 kWh | 0.25 to 0.9 | 0.13 | Can be cheaper |
| Price to host one rack (per month) | 0 to 10.000 | 483 | Can be cheaper |
| Interest rate for loan | 0% to 10% | 3% | Can be cheaper |
http://www.nexedi.com/NXD-Blog.Cloud.Computing.Potential.China
The figures we provided are similar in China except for networking. Land, electricity and loans can be heavily subsidised in China if one is Chinese and has good relations with the government.
However, internet transit is really expensive. What costs 150€ to 270€ in China costs at least 1,000€ (for the lucky few), 3,000€ (in big volumes) or 6,000€ (for the rest of us). This is 6 to 40 times more expensive.
Also, crossing the border can be very expensive. Official price of cross-border 2 Mbps line from China Unicom in 2018 was about 2,000€ per month.
There are different solutions to mitigate these high costs in China but they require deep understanding Chinese telecom ecosystem and are only available to Chinese nationals.
Low Cost Architecture
Some design decisions in Rapid.Space focus on lowering costs in any possible way. Let us review them.
Cost Killing
- No hardware redundancy (Redundancy through multiple data centres)
- No IPMI
- Public IPv6 range (no routable IPv4)
- IPv6/IPv4 CDN (HTTP3 incl. China)
- Outgoing IPv4/IPv6 whitelist (no DDOS)
Rapid.Space approach to redundancy is called "data centre" redundancy. Inside a data centre, there is no redundancy. If one is looking for redundancy, one should obtain it my deploying another server in another data centre. Based on statistics collected by IWGCR (www.iwgcr.org), no public cloud currently is able to provide effective high availability. However, by combining multiple cloud providers, one can reach this goal.
Based on this idea, we have single power source, single internet transit, single power supply, single SSD, single switch per rack, etc.
We do not use IPMI because it adds management complexity, costs and security issues. Instead we consider the server to be something that is "sent to the moon" and that is going to work for some time more or less reliably, including the base operating system (which ideally should become a signed read-only image downloaded directly by the bootloader and verified).
We only do IPv6, except for the CDN part (IPv4 and IPv6) and for the support of HADOOP clusters for which we provide private IPv4 addresses (HADOOP still has issues with IPv6 due to poor code).
We block all IPv4/IPv6 outgoing communication except for a whitelist that consists of public source repositories and user defined adresses. We charge 1€ for user defined address in the whitelist. This is like zero for a backend application but too expensive to host malware. We can thus save the costs of some complex DDOS filtering device.
I/O Performance: qemu /dev/sdb
| OCP qemu qcow2 | OCP qemu /dev/sdb2 | OCP qemu /dev/sdb | OCP bare metal | OVH OpenStack | OVH Dedicated | |
|---|---|---|---|---|---|---|
| Duration | 85h | 85h | 12h55 | 9h51 | 16h22 | 8h27 |
| VM Manager | SlapOS | SlapOS | SlapOS | N/A | OpenStack | N/A |
| Orchestrator | SlapOS | SlapOS | SlapOS | SlapOS | SlapOS | SlapOS |
| Database | NEO + InnoDB | NEO + InnoDB | NEO + InnoDB | NEO + InnoDB | NEO + InnoDB | NEO + InnoDB |
| Pystone (CPU test) | 150.000 | 150.000 | 150.000 | 150.000 | 200.000 | 230.000 |
| vCore | 40 | 40 | 40 | 40 | 64 | 40 |
| Xeon Generation | v2 | v2 | v2 | v2 | N/A | v3 |
| Frequency | 2.8/3.6 GHz | 2.8/3.6 GHz | 2.8/3.6 GHz | 2.8/3.6 GHz | 3.1 GHz | 2.6/3.3 GHz |
| Storage | 4 TB SATA SSD | 4 TB SATA SSD | 4 TB SATA SSD | 4 TB SATA SSD | 4 TB High Speed | 4 TB NVME SSD |
| RAM | 256 GB | 256 GB | 256 GB | 256 GB | 2 x 120 GB | 256 GB |
| Monthly Price | N/A | N/A | 195€ | 195€ | 2261€ | 769€ |
| Redundancy | No | No | No | No | Yes | No |
We use a single attached SSD tuned for highest performance. This provides much faster results than block storages in our tests ("OVH OpenStack") and only 30% write performance loss compared to bare metal "OCP bare metal"). Yet, a high end dedicated server from OVH is still more powerful than Rapid.Space (and more expensive).
Software: SlapOS
Rapid.Space runs with SlapOS cloud operation and orchestration system. SlapOS is an overlay on top of Linux or any POSIX compliant OS.
SlapOS: (one of) the first edge computing systems
https://www.cio.com/article/2417512/servers/vifib-wants-you-to-host-cloud-computing-at-home.html
We've been deploying edge computing at Nexedi since around 2008 with SlapOS.
Everyone has a different notion of edge computing. We tried to define them in this article: Five Evolutions of Cloud Computing "https://www.nexedi.com/NXD-Blog.Five.Cloud.Evolution". However, Edge Computing is kind of buzzword that covers many old ideas of distributed computing that recently became more widely accepted.
Fully Documented
- https://slapos.nexedi.com/
- SlapOS General Introduction (Presentation)
- SlapOS Technical Architecture (Presentation)
- SlapOS System Requirements (Presentation)
- Installing SlapOS Master (COMP-Root) (Presentation)
- Installing SlapOS Node (COMP-0) (Presentation)
- Installing SlapOS Node (COMP-123) (Presentation)
- Manage a SlapOS System (Presentation)
- Monitoring a SlapOS Node (Presentation)
- Invoice SlapOS Network Usage (Planned)
- etc.
SlapOS is fully documented. The documentation consists of design documents and tutorials that present on https://slapos.nexedi.com/ web site.
Documentation that actually works
Partly sponsored by Free Software Endowment Fund (FDL) thanks to Amarisoft donation
It takes 2 days to do all tutorials for an experienced Linux developer
It take 2 weeks to do all tutorials for someone who never touched Linux in his life
It takes one month for a Télécom ParisTech graduate and experienced engineer to learn how to manage the whole platform.
Documentation was sponsored by the Free Software Endowment Fund (FDL) thanks to Amarisoft donation.
Why don't you use OpenStack?
We often get questions such as:
- why don't you use virtualisation?
- why don't you OpenStack?
- why don't you use Docker?
- etc.
We usually answer: because they don't work according to industrial grade standards, even now, and because they did not exist in 2008.
The meaning of "does not work" is a bit different for Nexedi and for most open source developers. In Nexedi, we want systems that "work always in the same way and for a very long time", rather than systems that "work sometimes" and are easy to install with a beautiful web site. We want this kind of predictability for everything (build, ordering, etc.). We care more about improving our software than community or documentation. If a solution works but is rejected by most community, we ignore community because we have to serve our customers first (our business model is based on customers, not on venture capital).
So, in the case of OpenStack, we believe that its architecture is not promise based and can thus never be stable. This is explained with more details in "Five Evolutions of Cloud Computing".
We also tried to use OpenStack VMs from various suppliers, including OVH, Rackspace and some governments clouds. We did some statistics on hundreds of servers. The conclusion was terrible: there are in average three times more unexpected reboots of OpenStack VMs than on a micro-server hosted in someone's home without UPS.
Another conclusion is that OVH bare metal servers are remarkably stable. Servers will reboot unexpectedly in average once a decade.
Why don't you use LXC/Docker?
- Not portable across Linux distros
- Not supported outside Linux
- Still a bit unpredictable on Linux
~ $ free -h
https://www.nexedi.com/NXD-Blog.Docker.SlapOS.Nano.Container.Elbe
The article "Are Linux containers stable enough for production and why Nexedi uses SlapOS nano-containers instead ?" (https://www.nexedi.com/NXD-Blog.Docker.SlapOS.Nano.Container.Elbe) explains for example why we do not use Docker or LXC containers and why we do not plan to use them for ourselves. Until recently, it was very difficult to find anyone who would agree with us (just like OpenStack 10 years ago). But more and more people now understand the problems of binary portability with Linux kernel and its consequence on Docker/LXC containers.
So, we might use "kernel namespaces" with SlapOS.
SlapOS could easily support docker/LXC type containers; we actually already implemented it. But those docker/LXC containers will only work if some strict conditions are met: host OS/Kernel and guest OS/Kernel should be same for example. Sadly most developers do not understand those conditions and do not respect them. It is thus difficult to provide something that works according to our standards.
SlapOS Design
Let us now review SlapOS architecture and design goals.
Everything is a Service
- A database service
- A kvm service
- A routing service
- An HTTP cache service
- An ERP service
- etc.
In Unix, everything is a file.
In SlapOS, everything is service.
A database is service. A qemu runtime is a service. A routing daemon is a service. An HTTP cache is a service. An ERP is a service.
Every service has a URL that defined how to communicate with it.
Multiple services communicating together can be assembled as a complex service.
Everything is a Service
~ $ slapos request mariadb my_db
~ $ slapos request kvm my_vm
~ $ slapos request re6st-registry my_registry
~ $ slapos request cdn my_cdn
~ $ slapos request erp5 my_erp
Therefore, in SlapOS, there is no difference between IaaS, SaaS, PaaS, NaaS or any XaaS.
It is just about requesting X as a service by calling slapos request.
Design Goals: Unify Service Description
- no matter where
- no matter when
- no matter what
- no matter which distro or OS (POSIX)
- no matter which version of distro
- no matter which architecture
- no matter complexity
- with real time, high peformance and resiliency support
- and at lowest possible cost
What mattered to Nexedi when SlapOS was created is that whatever service we would deploy, we wanted to be able to deploy it fully automatically using the same "service descriptor language", no matter:
- where (data centre, on premise, inside an airplane, on a smartphone, inside a sensor, etc.);
- when (today, in 5 years, in 10 years, etc.);
- what (database service, VM service, application sever service, smart sensor processing service, data buffering service, etc.);
- which distro (Debian, Ubuntu, Fedora, CentOS, FreeBSD, SuSE, RedHat, Arch, etc.);
- which version of distro (2016, 2017, 2018, etc.);
- which architecture (bare metal, VM, x86, ARM, etc.);
- complexity (unitary service, orchestration of dozens services);
- real time constraints (no constraint, hard real time).
Service Unification from Edge to Space
Ideally, SlapOS should deploy on smartphones, 5G gNodeB, central servers, drones, satellites, etc. using the same unified service description approach.
SlapOS was actually deployed some years ago inside a 777 flight of JAL between Paris and Tokyo, serving real time web content during the journey.
Design Goals: Automate Service Lifecycle
- catalog (of services)
- build
- test
- ordering
- provisioning
- configuration
- orchestration
- monitoring
- issue tracking
- accounting
- billing
- disaster recovery
We wanted our solution to cover all aspects of the lifecycle of service:
- catalog of available services (appstore);
- build;
- ordering;
- provisioning;
- configuration;
- orchestration;
- monitoring;
- issue tracking;
- accounting;
- billing;
- disaster recovery (incl. ability to rebuild everything after 10 years):
Design Goals: Security and Resiliency
- insecure network
- unstable network
- unstable hardware
- unstable electricity
- vanishing code sources
And we wanted our solution to be take into account "real world" features of public infrastructures which we had observed and made statistics of:
- insecure network (anyone can spy it);
- unstable network (packets are lost, connectivity is lost);
- unstable hardware (any component can crash);
- unstable electricity (electricity shortage is always possible).
The article "Downtime statistics of current cloud solutions" (http://iwgcr.org/wp-content/uploads/2013/06/IWGCR-Paris.Ranking-003.2-en.pdf) should give a good overview of the lack of resiliency of cloud, networking and electricity no matter who is the supplier.
Promise Based Minimalist Architecture
- Master: ERP5 (promise definition, ordering, provisioning, accounting, billing, issue tracking)
- Slave: buildout (promise execution, build, instantiation, configuration, monitoring)
So, we used buildout (http://docs.buildout.org/en/latest/) as the base for our service descriptor language and ERP5 to keep track of "service lifecycle" after we found out that any edge or cloud system can be made of two components: a devops and an ERP (see "SlapOS: SlapOS: A Multi-Purpose Distributed Cloud Operating System Based on an ERP Billing Model" https://ieeexplore.ieee.org/document/6009348).
For resiliency, we based all our design on the idea that resiliency must be implemented with software and should rely on redundant infrastructure on redundant sites with redundant suppliers. However each site or hardware does not need to be redundant.
This approach was quite successful. By sticking to a very simple and minimal architecture, we could achieve with a small budget what huge community projects such as OpenStack still fail to achieve after 10 years. And we could do much more, because our architecture was more generic.
Advanced Features
- Recursivity: SlapOS Master can provision a SlapOS Master on a SlapOS Node
- Federation; SlapOS Master can delegate provisioning to another SlapOS Master
- Zero Knowledge: no secrets on SlapOS Master
SlapOS provides advanced features of a modern cloud and edge operation system.
With recursivity, SlapOS can deploy itself. It also means that SlapOS can test itself.
With federation, one SlapOS system can support services of another SlapOS system. For example one SlapOS system can delegate CDN to another SlapOS system that is able to supply it.
The idea of Zero Knowledge consists of ensuring that no secrets are shared in SlapOS master. It could also mean that SlapOS node provide no remote ssh.
Nano Containers
- declarative
- bare metal
- multiple versions
- multiple instances
- no superuser needed
- portable across Linux distributions (unlike Docker)
- portable to other POSIX OS (Android, FreeBSD, etc.)
- (option) source cache (encouraged)
- (option) binary cache
- (option) virtualisation
- (option) name spaces
- (option) containerisation (discouraged)
Nano containers in SlapOS simply means that SlapOS uses the standard POSIX isolation of unpriviledged users.
Thanks to buildout technology, it is declarative and runs on bare metal.
Multiple versions of the same software can be deployed at the same time on the same host. Multiple instances too.
All services are meant to run as a normal user (unpriviledged). We run nothing as root except the core SlapOS daemon (slapgrid). We patched any libraries that could not execute without root privileges (postfix) or hardcoded some path (ex. X11).
Thanks to buildout, SlapOS is portable across Linux distributions or even to other POSIX systems such as Android, FreeBSD, MacOS. It is just a matter of extending the buildout profile to take into account specific compilation options for each platform.
Source code can be cached to ensure that it can be rebuilt after ten years.
Binaries can be cached (and shared) to accelerate installation.
SlapOS can run inside or outside a virtual machine. It can deploy virtual machines too.
It can support namespaces or cgroups if necessary.
It can even deploy LXC/Docker type containers but this is something we discouraged for reasons explained previously.
Linuxboot
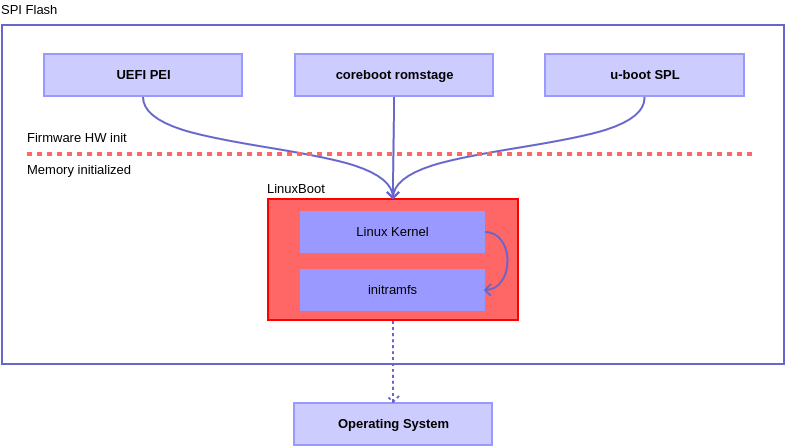
LinuxBoot is a firmware for modern servers that replaces specific firmware functionality like the UEFI DXE phase with a Linux kernel and runtime. Why? Improves boot reliability by replacing lightly-tested firmware drivers with hardened Linux drivers. Improves boot time by removing unnecessary code. Typically makes boot 20 times faster. Allows customization of the initrd runtime to support site-specific needs (both device drivers as well as custom executables). Proven approach for almost 20 years in military, consumer electronics, and supercomputing systems – wherever reliability and performance are paramount.
re6st
re6st was created to fix problems of current Internet through an IPv6 overlay network.
In today's Internet, latency is usually sub-optimal and telecommunication providers provide unreliable transit. There are lots of network cuts. DPI systems introduce sometimes data corruption in basic protocols (ex. TCP). Governments add censorship and bogus routing policies, in China for example. There is no way to ensure that two points A and B on the Internet can actually interconnect. The probability of connectivity fault is about 1% in Europe/USA and 10% inside China. It is too much for industrial applications.
Without re6st, SlapOS (or any distributed container system) can not work. If one has to deploy 100 orchestrated services over a network of edge nodes with a 1% probability of faulty routes, the overall probability of failure quickly becomes too close to 100%. There is therefore no way to deploy edge without fixing the Internet first.
This is very easy to understand in China. But it is also true in Europe and USA (maybe not yet in Japan).
re6st routing provides one solution to that. re6st is available in China (license: 中华人民共和国增值电信业务经营许可证:沪A1-20140091). Nexedi has the right to provide global low latency high resiliency IPv6 network for IoT.
In addition to re6st, we use buffering to that we do not lose data sent by edge nodes (gateways or sensors) in case of application server failure for example:
Both re6st and fluentd are used in all IoT deployments done by Nexedi and based on SlapOS.
Other SlapOS Success Cases
Let us have a look at some success cases that also use SlapOS beyond Rapid.Space. This will give an idea of possible evolution for Rapid.Space.
Success Case: WebRunner IDE
SlapOS "Web Runner" is a Web based IDE. It is used in Nexedi to develop all projects for its customers. Nexedi runs thousands of Web Runners on its global infrastructures. Developers only need a Web Browser and a single "slapos request" to get their development environment, which is now automated and unified across entities.
Success Case: Grandenet Global CDN
Grandenet (China) runs re6st and an HTTP2/QUIC CDN all over the world including in China.
Success Case: Teralab
https://www.nexedi.com/success/slapos-IMT-Documents.Teralab.Success.Case
Teralab runs a big data infrastructure for French government. See: https://www.nexedi.com/success/slapos-IMT-Documents.Teralab.Success.Case.
Success Case: Data Collector
Woefel (Germany) collects data from hundreds of wind turbines using fluentd which is itself deployed using SlapOS (server side). An experimental extension can deploy fluentd in the sensor directly and use a GPU to process signal in real time.
Success Case: LTE/NR SDR NMS
https://www.nexedi.com/NXD-Document.Press.Release.NMS.Preview.MWC.2018
SlapOS was extended as a Network Management System (NMS) for LTE/NR networks. It deploys SDR and configures the bare metal Linux for hard real time signal processing through cgroup configuration.
See 5G Edge Computing VRAN with SlapOS and Amarisoft: https://www.nexedi.com/news/NXD-Blog.5G.Edge.VRAN
Success Case: Factory-in-a-box

Automated deployment of "smart factory box" for some automotive company in new factories located in smaller countries. All kinds of services can be remotely such as ERP, CDN, MES, etc.
Future
The future of Rapid.Space depends on the future of SlapOS and on contributions to SlapOS by community.
Because Rapid.Space is using solely Free Software (including billing), anyone can improve Rapid.Space service (including billing).
SlapOS Roadmap
- Jupyter-lab
- Secure Boot: ELBE RFS
- Software Defined Sensor: PREEMPT_RT
- Edge Gateway: OPC-UA, DDS
- Radio Router: HCCA, TD-Wifi, NR
SlapOS will son include support for Jupyter-lab, a secure boot based on ELBE (Linutronix).
We hope to support hard real time in sensors with PREEMPT_RT.
We hope to add support for industrial automation using OPC-UA and maybe DDS.
We also hope to create routers based on SlapOS and including time division radio networks (Wifi, NR) for deterministic communication in the factory.
Rapid.Space Roadmap
- Bare metal database- (MariaDB, NEO)
- Bare metal nano containers
- Community Contributions (ex. PostgreSQL)
- 48 vCore
- Additional FusionIO / NVME disk
- GPU
Rapid.Space will soon provide high performance database servers running bare metal on FusionIO or NVME disks.
We hope community will contribute more servers beyond MariaDB or NEO.
New OCP servers will be based on v3 Xeon with 48 cores and possibly GPU.
References
- https://slapos.nexedi.com/ contains the documentation and tutorials, especially some architecture introduction
- https://www.ctocio.com/tech/computing/16071.html explains how SlapOS solves problems similar to those solved by Plan9 but using "services" rather than "files".
You can find more articles related to SlapOS:
- https://slapos.nexedi.com/ contains the documentation and tutorials, especially some architecture introduction
- https://www.ctocio.com/tech/computing/16071.html explains how SlapOS solves problems similar to those solved by Plan9 but using "services" rather than "files".
- https://www.cio.com/article/2417512/servers/vifib-wants-you-to-host-cloud-computing-at-home.html was the first press article when we started to deploy "cloud servers at home" which can be considered as one type of edge computing
Thank You
- Nexedi SA
- 147 Rue du Ballon
- 59110 La Madeleine
- France
QR Code
This presentation can be shared using the QR displayed above.
Thank You
- Nexedi SA
- 147 Rue du Ballon
- 59110 La Madeleine
- France
- +33629024425
For more information, please contact Jean-Paul, CEO of Nexedi (+33 629 02 44 25).