
QR
This presentation is published online at the URL: https://www.nexedi.com/NXD-Presentation.SlapOS.NMS.POSS.2018/WebPage_viewAsWeb?portal_skin=Slide#. You can scan the QR above to open it on your mobile phone.
Agenda
- Nexedi
- It's christmas
- History
- Design
- Future
We will first provide an overview of SlapOS NMS for LTE/NR networks, probably the first network management system available as Free Software. It's Christmas.
Next, we will introduce the history of SlapOS.
We will then focus on the key design strengths of SlapOS.
At the end we will announce our roadmap for future NMS features based on SlapOS.
Nexedi
Nexedi - Profile
- Largest Free Software Publisher in Europe
- Founded in 2001 in Lille (France) - 35 engineers worldwide
- Enterprise Software for mission critical applications
- Build, deploy, train and run services
- Profitable since day 1, long term organic growth
Nexedi - Clients
Nexedi clients are mainly large companies and governments looking for scalable enterprise solutions such as ERP, CRM, DMS, data lake, big data cloud, etc.
Nexedi - Free Software Stack
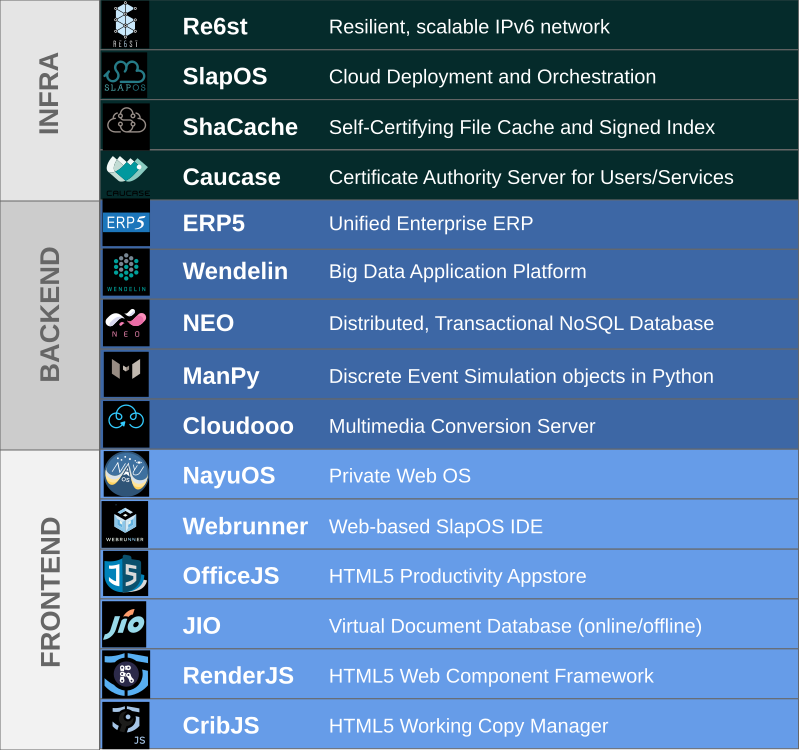
Nexedi software is primarily developed in Python, with some parts in Javascript.
It's christmas
It's soon Christmas. Nexedi is happy to give to the community a new software: SlapOS Network Management System (NMS) for LTE/NR networks. It is probably the first commercial grade Network Management System on the market.
Grands Défis du Numérique
SlapOS NMS was partly financed by the OSTV project, an industrial R&D project financed by French government as part of "Grands Défis du Numérique" programme. The OSTV project itself is implemented by a group of French small businesses member of the Systematic competitive cluster (Amarisoft, SDS, BJG Partners, AW2S) and Paris 7 University.
LTE/NR Network Management with SlapOS
https://www.nexedi.com/NXD-Document.Press.Release.NMS.Preview.MWC.2018 (PDF)
SlapOS has been extended to act as a Network Management System (NMS) for LTE/NR networks. It deploys SDR services and configures the bare metal Linux operating system for hard real time signal processing through cgroup configuration. It provides a modern HTML5 user interface to manage commercial grade networks.
It was first announced at MWC2018. It was then released entirely in October 2018 with complete documentation.
The main purpose of an NMS is to get a real time overview of a network (deployed hardware, running services, current subscribers), be informed of any incident, track incident resolution through a ticket and eventually produce invoices based on service agreements with the different parties involved.
On this picture, open tickets are list on the bottom of the screenshot, under the map which shows the state of base stations.
eNodeB provisioning with SlapOS
One of the first steps in using SlapOS NMS is to provision a remote eNodeB very simply using a stable set of configuration parameters. This way, whenever the eNodeB vendors changes configuration formats from one version to another, upgrade if possible transparently with same parameters.
Base Station Management with SlapOS
Once the eNodeB is provisioned on the remote hardware, we want to be informed (through a ticket) that something is going wrong, as soon as it goes wrong. Here we see a lost of base stations. One of them has been shutdown and is red.
eNodeB Drill-down with SlapOS (1)
Next, we want to track if any service is in wrong state. Here we see that one eNodeB service is wrong.
eNodeB Drill-down with SlapOS (2)
We can then drill down and look at service promises. The concept of promises comes from Mark Burgress and is at the core of any modern monitoring system.
eNodeB Drill-down with SlapOS (3)
In case a promise is down, we need be able to drill-down any parameters or log in case of incident.
Although this kind of picture is often associated with NMS, we should still keep in monde that the true purpose of an NMS is to automate the incident detection and resolution process through promises and tickets. Drilling-down should only be used as part of the incident resolution process but should not be considered as the purpose of NMS.
SlapOS NMS Features
- It works (Teralab, Grandenet, Automotive, Rapid.Space, etc.)
- It is entirely Free Software
- It isentirely documented (thanks to Amarisoft)
- It is supported commercialy (pricing here)
- It supports SDR (Amarisoft now, others in 2019)
- It will support dedicated hardware (ex. Baicells, others if they like)
What makes SlapOS different with many other Free Software intended for telecommunication (or even cloud computing) is that it really works. It is not just a research project, or a bloated community project, or a proof-of-concept, or an innovation platform. It is a mature, commercial grade, carrier grade system that has been design for reliable operation. It is based on SlapOS mature technology which are already deployed in numerous applications: Teralab big data centre, Grandenet resilient CDN, edge computiing in automotive factories, Rapid.Space low cost high performance cloud, etc.
It is of course entirely Free Software. There is no hidden commercial license or patent license. We are based in Europe and thus software patents are simply "contra legem " (as it was reminded by Paris court of Justice in the case "Orange vs. Free"). So, nobody will have to sign any document with us to recognise some patents on mere mathematical formulae.
It is entirely documented. You can find a complete tutorial of 300 pages that teaches how to become a telecommunication operator: https://www.erp5.com/P-OSTV-Tutorial.Nms.Learning.Track. A good engineer who graduated from Telecom ParisTech can finish this tutorial in about 2 days and acquire the rest of know how in about 2 months. This is extremely short if we compare this duration to - for example - the failure of French government sponsored sovereign cloud after years of public money waste.
It is supported commercially by Nexedi. We even provide now a standard pricing: https://www.nexedi.com/fr/VIFIB-Pricing.2016.
We support Amarisoft stack for now, which is sadly proprietary, yet works very reliably for commercial deployments and supports the latest LTE/NR features including NB-IoT and carrier aggregation. We hope to support in 2019 more stacks such as SRS or OAI.
We will also support in 2019 hardware eNodeB, starting with Baicells. Baicells provides complete hardware (eNodeB and RRH) that is cheaper than Amarisoft license price and that is available.
SlapOS NMS Scope
- LTE/NR eNodeB provisioning and monitoring
- EPC provisioning and monitoring
- SIM provisioning and management
- Base station management and monitoring
- Centralised or distributed VRAN (PHY)
- Centralised or distributed core network
- Resilient IPv6 low latency backhaul based on hybrid mesh
- Edge acceleration (ex. https)
- Edge buffering (ex. fluentd)
- Edge offloading (ex. storage, A.I.)
- Accounting and billing
- Predictive maintenance
SlapOS NMS features are quite wide.
First, we can provision and monitor LTE/NR eNodeB, EPC and SIM card database. We can manage and monitor the base station hardware which runs the SDR stack.
We support both centralised core network (one EPC, multiple eNodeB) and decentralised core network (one EPC, one eNodeB) models. In the decentralised case, we invented a new approach for data handover, which will be published in 2019.
We also support both centralised VRAN (one eNodeB server, multiple RRH) or decentralised VRAN (one eNodeB server, one RRH).
SlapOS NMS includes a resilient IPv6 backhaul which combines all forms of transit (wired, wireless) into a a hybrid mesh and ensures at any time low latency routing.
SlapOS NMS is a converged system. It acts as a traditional NMS but also as an edge platform. Different forms of edge services (https acceleration, fluent IoT buffering, storage offloading, A.I. offloading, etc.) can be deployed on the same base station hardware as the one which runs the SDR stack. This means that whenever one deploys a complete network,it is possible to define the network in a completely encapsulated way which combines all layers, from physical virtualisation (Layer 2) to application (Layer 7). All layers are mutually configured, optimised and orchestrated.
SlapOS NMS supports of course accounting and billing. One of the two SlapOS components is originally an ERP: ERP5. It can support billing generation at a speed of 80.000 invoices per hour.
SlapOS NMS also includes PyData and scikit-learn as well as out-of-core storage and machine learning. It is thus capable of predictive maintenance.
Success Case: Grandenet Global CDN
Every feature of SlapOS NMS has been deployed commercially, except SDR eNodeB / EPC.
For example, Grandenet provides an HTTP2/QUIC CDN all over the world including in China (with government license).
This is one example of edge computing implemented for real by SlapOS NMS.
Success Case: Data Collector
Woefel (Germany) collects data from hundreds of wind turbines using fluentd which is itself deployed using SlapOS (server side). An experimental extension can deploy fluentd in the sensor directly and use a GPU to process signal in real time.
This is another example of edge computing deployed by SlapOS NMS.
Success Case: Rapid.Space
Rapid.Space (https://rapid.space/) is a high performance, low cost cloud infrastructure that provides:
- big servers;
- CDN;
- (soon) IoT buffering.
It is available in Europe and soon in China through partner company. It is based on SlapOS and Open Compute Project (OCP) hardware, the same as the one used by Facebook.
Everything about Rapid.Space is public.
- Business Model: https://www.nexedi.com/NXD-Blog.Low.Cost.Cloud.Business.Model
- Performance Optimisation: https://www.nexedi.com/NXD-Blog.High.Performance.VM.DB
- Source Code: https://slapos.nexedi.com
SlapOS NMS Applications
- Commercial LTE/NR network (10s to 1.000s sites, possibly more )
- Public LTE/NR as a Service (ex. parking)
- Private LTE/NR as a Service (ex. factories)
- Edge and Central Office unification
- Convergence between IT and networking
So, as we can see, SlapOS NMS really works. The only case for which we still have no commercial deployment is... eNodeB/EPC.
The reasons are multiple:
- it is difficult to get licensed frequencies;
- it has been difficult to get open standard RRH from telecom vendors;
- telecom operators are conservative;
- telecom operators are forced to obey possibly abusive maintenance contracts imposed by telecom vendors.
The current market situation can thus be described as follows.
With SlapOS NMS, there is a commercial grade solution to deploy commercial LTE/NR networks of 10s to 1000s site (possibly even more), to provide LTE/NR as a service in public areas (ex. parkings) or private areas (ex. factories), solve the problem of edge and central office unification or accelerate convergence between IT and networking.
This commercial exists, is proven for now 10 years in various applications but is blocked from being applied to LTE/NR networking by all kinds of artificial, anti-competitive market behaviours.
We therefore announce today: we will support for free for one year the first company which decides to deploy SlapOS NMS for a commercial LTE/NR network with commercial users (not a POC).
It is time to break anti-competitive market behaviours in the LTE/NR infrastructure business.
It is time to break a market behaviour which leads French government to provide through ARCEP 3 billions euros of subsidies to telecommunication operators so that they cover French rural areas with 3G when it would actually cost 200 million euros to cover rural in 5G with SlapOS NMS based solution. (see https://www.nexedi.com/fr/press/news-VIFIB.5G.Launch)
SlapOS RRH Ecosystem
- AW2S
- Air-Lynx
- BJT Partners
- Secret but very famous
- Also secret and also very famous
- Lime Micro (open hardware)
- Whoever opens their CPRI / Ethernet payload
- Huge opportunity for Open Hardware RRH (OCP, TIP)
The first step to break anti-competitive market behaviours has been achieved in 2018.
Without remote radio head (RRH), there is no possible commercial deployment. Sadly, the big four (Huawei, ZTE, Nokia, Alcatel) refuse to open their protocols. They refuse to provide the format of payloads sent over the CPRI interface. They even refuse to sell standalone RRH. This prevents using their hardware to deploy commercial networks.
It is possible to source RRH from other suppliers (AW2S, Air-Lynx, BJT Partners). However, either price is too expensive or availability is scarce. Yet, Air-Lynx was used already to provide LTE on the Paris-Lyon TGV line. This is a proof that commercial deployment is possible.
The good news of 2018 is that two vendors of RRH are now supported by SlapOS NMS using Amarisoft stack. They are reputable vendors of RRH that are already commercially deployed by some of the largest telecom operators. Their name will remain secret (by fear of the big four).
Another issue is that there are no CPRI-PCI cards that are based on open source drivers. Drivers of CPRI-PCI cards by Amarisoft or AW2S are proprietary. They force the use of a given SDR stack or of a given RRH. Even worse, they force the use of a given Linux kernel version. It is in our opinion a dead-end that replicates the kind of anti-competitive behaviours experienced already with the big four.
In our opinion, only open hardware and open source drivers make sense. This is exactly what Lime Micro is doing with their range of SDR products. Hopefully, Lime Micro will release an RRH in open hardware.
What we need now is someone to create and release a CPRI-PCI card in open hardware (10 Gbps).
History
SlapOS is an overlay on top of Linux or any POSIX compliant OS. It can act as a general purpose edge computing system, cloud computing or orchestration system.
SlapOS: (one of) the first edge computing systems
https://www.cio.com/article/2417512/servers/vifib-wants-you-to-host-cloud-computing-at-home.html
We've been deploying edge computing at Nexedi since around 2008 with SlapOS.
Everyone has a different notion of edge computing. We tried to define them in this article: Five Evolutions of Cloud Computing "https://www.nexedi.com/NXD-Blog.Five.Cloud.Evolution". However, Edge Computing is kind of buzzword that covers many old ideas of distributed computing that recently became more widely accepted.
Why don't you use OpenStack?
We often get questions such as:
- why don't you use virtualisation?
- why don't you OpenStack?
- why don't you use Docker?
- etc.
We usually answer: because they don't work according to industrial grade standards, even now, and because they did not exist in 2008.
The meaning of "does not work" is a bit different for Nexedi and for most open source developers. In Nexedi, we want systems that "work always in the same way and for a very long time", rather than systems that "work sometimes" and are easy to install with a beautiful web site. We want this kind of predictability for everything (build, ordering, etc.). We care more about improving our software than community or documentation. If a solution works but is rejected by most community, we ignore community because we have to serve our customers first (our business model is based on customers, not on venture capital).
So, in the case of OpenStack, we believe that its architecture is not promise based and can thus never be stable. This is explained with more details in "Five Evolutions of Cloud Computing".
We also tried to use OpenStack VMs from various suppliers, including OVH, Rackspace and some governments clouds. We did some statistics on hundreds of servers. The conclusion was terrible: there are in average three times more unexpected reboots of OpenStack VMs than on a micro-server hosted in someone's home without UPS.
Another conclusion is that OVH bare metal servers are remarkably stable. Servers will reboot unexpectedly in average once a decade.
Why don't you use LXC/Docker?
- Not portable across Linux distros
- Not supported outside Linux
- Still a bit unpredictable on Linux
~ $ free -h
https://www.nexedi.com/NXD-Blog.Docker.SlapOS.Nano.Container.Elbe
The article "Are Linux containers stable enough for production and why Nexedi uses SlapOS nano-containers instead ?" (https://www.nexedi.com/NXD-Blog.Docker.SlapOS.Nano.Container.Elbe) explains for example why we do not use Docker or LXC containers and why we do not plan to use them for ourselves. Until recently, it was very difficult to find anyone who would agree with us (just like OpenStack 10 years ago). But more and more people now understand the problems of binary portability with Linux kernel and its consequence on Docker/LXC containers.
So, we might use "kernel namespaces" with SlapOS.
SlapOS could easily support docker/LXC type containers; we actually already implemented it. But those docker/LXC containers will only work if some strict conditions are met: host OS/Kernel and guest OS/Kernel should be same for example. Sadly most developers do not understand those conditions and do not respect them. It is thus difficult to provide something that works according to our standards
Design
Let us now review SlapOS architecture and design goals.
Everything is a Service
- A database service
- A kvm service
- A routing service
- An HTTP cache service
- An ERP cache service
- An eNodeB SDR service
- An eNodeB proxy service
- An EPC service
- etc.
In Unix, everything is a file.
In SlapOS, everything is service.
A database is service. A qemu runtime is a service. A routing daemon is a service. An HTTP cache is a service. An ERP is a service.
Same goes for SDR: An eNodeB is a service running on a EPC. An EPC is a service
And if we use hardware eNodeB, the proxy runtime that communicates with the eNodeB to configure it is also a service
Every service has a URL that defined how to communicate with it.
Multiple services communicating together can be assembled as a complex service.
SlapOS: Service Operation Automation
~ $ slapos request mariadb my_db
~ $ slapos request kvm my_vm
~ $ slapos request re6st-registry my_registry
~ $ slapos request cdn my_cdn
~ $ slapos request erp5 my_erp
~ $ slapos request amarisoft_enb my_enb
~ $ slapos request amarisoft_epc my_epc
~ $ slapos request amarisoft_mbms my_mbms
~ $ slapos request srs_enb my_enb2
~ $ slapos request srs_epc my_epc2
~ $ slapos request oai_enb my_enb3
Therefore, in SlapOS, there is no difference between IaaS, SaaS, PaaS, NaaS or any XaaS.
It is just about requesting X as a service by calling slapos request.
NMS for LTE/NR is just an application of XaaS where X is SDR.
Ideally, SlapOS NMS will be able some day to deploy any SDR. For now, we support Amarisoft SDR because it is the best. However, since it is proprietary, it is impossible to ensure that it will remain available in the next 10 years, and it is difficult to extend it to support new innovative features without support from Amarisoft. It is thus important for Nexedi to make sure other SDR also work with SlapOS NMS and demonstrate ability to act as a global solution.
Design Goals: Unify Service Description
- no matter where
- no matter when
- no matter what
- no matter which distro or OS (POSIX)
- no matter which version of distro
- no matter which architecture
- no matter complexity
- with real time, high peformance and resiliency support
- and at lowest possible cost
What mattered to Nexedi when SlapOS was created is that whatever service we would deploy, we wanted to be able to deploy it fully automatically using the same "service descriptor language", no matter:
- where (data centre, on premise, inside an airplane, on a smartphone, inside a sensor, etc.);
- when (today, in 5 years, in 10 years, etc.);
- what (database service, VM service, application sever service, smart sensor processing service, data buffering service, etc.);
- which distro (Debian, Ubuntu, Fedora, CentOS, FreeBSD, SuSE, RedHat, Arch, etc.);
- which version of distro (2016, 2017, 2018, etc.);
- which architecture (bare metal, VM, x86, ARM, etc.);
- complexity (unitary service, orchestration of dozens services);
- real time constraints (no constraint, hard real time).
Service Unification from Edge to Space
Ideally, SlapOS should deploy on smartphones, 5G gNodeB, central servers, drones, satellites, etc. using the same unified service description approach.
SlapOS was actually deployed some years ago inside a 777 flight of JAL between Paris and Tokyo, serving real time web content during the journey.
Design Goals: Automate Service Lifecycle
- catalog (of services)
- build
- test
- ordering
- provisioning
- configuration
- orchestration
- monitoring
- issue tracking
- accounting
- billing
- disaster recovery
We wanted our solution to cover all aspects of the lifecycle of service:
- catalog of available services (appstore);
- build;
- ordering;
- provisioning;
- configuration;
- orchestration;
- monitoring;
- issue tracking;
- accounting;
- billing;
- disaster recovery (incl. ability to rebuild everything after 10 years):
Design Goals: Security and Resiliency
- insecure network
- unstable network
- unstable hardware
- unstable electricity
- vanishing code sources
And we wanted our solution to be take into account "real world" features of public infrastructures which we had observed and made statistics of:
- insecure network (anyone can spy it);
- unstable network (packets are lost, connectivity is lost);
- unstable hardware (any component can crash);
- unstable electricity (electricity shortage is always possible).
The article "Downtime statistics of current cloud solutions" (http://iwgcr.org/wp-content/uploads/2013/06/IWGCR-Paris.Ranking-003.2-en.pdf) should give a good overview of the lack of resiliency of cloud, networking and electricity no matter who is the supplier.
Promise Based Minimalist Architecture
- Master: ERP5 (promise definition, ordering, provisioning, accounting, billing, issue tracking)
- Slave: buildout (promise execution, build, instantiation, configuration, monitoring)
So, we used buildout (http://docs.buildout.org/en/latest/) as the base for our service descriptor language and ERP5 to keep track of "service lifecycle" after we found out that any edge or cloud system can be made of two components: a devops and an ERP (see "SlapOS: SlapOS: A Multi-Purpose Distributed Cloud Operating System Based on an ERP Billing Model" https://ieeexplore.ieee.org/document/6009348).
For resiliency, we based all our design on the idea that resiliency must be implemented with software and should rely on redundant infrastructure on redundant sites with redundant suppliers. However each site or hardware does not need to be redundant.
This approach was quite successful. By sticking to a very simple and minimal architecture, we could achieve with a small budget what huge community projects such as OpenStack still fail to achieve after 10 years. And we could do much more, because our architecture was more generic.
Advanced Features
- Recursivity: SlapOS Master can provision a SlapOS Master on a SlapOS Node
- Federation; SlapOS Master can delegate provisioning to another SlapOS Master
- Zero Knowledge: no secrets on SlapOS Master
SlapOS provides advanced features of a modern cloud and edge operation system.
With recursivity, SlapOS can deploy itself. It also means that SlapOS can test itself.
With federation, one SlapOS system can support services of another SlapOS system. For example one SlapOS system can delegate CDN to another SlapOS system that is able to supply it.
The idea of Zero Knowledge consists of ensuring that no secrets are shared in SlapOS master. It could also mean that SlapOS node provide no remote ssh.
Nano Containers
- declarative
- bare metal
- hard real time
- multiple versions
- multiple instances
- no superuser needed
- portable across Linux distributions (unlike Docker)
- portable to other POSIX OS (Android, FreeBSD, etc.)
- (option) source cache (encouraged)
- (option) binary cache
- (option) virtualisation
- (option) name spaces
- (option) containerisation (discouraged)
Nano containers in SlapOS simply means that SlapOS uses the standard POSIX isolation of unpriviledged users.
Thanks to buildout technology, it is declarative and runs on bare metal.
Multiple versions of the same software can be deployed at the same time on the same host. Multiple instances too.
All services are meant to run as a normal user (unpriviledged). We run nothing as root except the core SlapOS daemon (slapgrid). We patched any libraries that could not execute without root privileges (postfix) or hardcoded some path (ex. X11).
Thanks to buildout, SlapOS is portable across Linux distributions or even to other POSIX systems such as Android, FreeBSD, MacOS. It is just a matter of extending the buildout profile to take into account specific compilation options for each platform.
Source code can be cached to ensure that it can be rebuilt after ten years.
Binaries can be cached (and shared) to accelerate installation.
SlapOS can run inside or outside a virtual machine. It can deploy virtual machines too.
It can support namespaces or cgroups if necessary.
It can even deploy LXC/Docker type containers but this is something we discouraged for reasons explained previously.
re6st
re6st was created to fix problems of current Internet through an IPv6 overlay network.
In today's Internet, latency is usually sub-optimal and telecommunication providers provide unreliable transit. There are lots of network cuts. DPI systems introduce sometimes data corruption in basic protocols (ex. TCP). Governments add censorship and bogus routing policies, in China for example. There is no way to ensure that two points A and B on the Internet can actually interconnect. The probability of connectivity fault is about 1% in Europe/USA and 10% inside China. It is too much for industrial applications.
Without re6st, SlapOS (or any distributed container system) can not work. If one has to deploy 100 orchestrated services over a network of edge nodes with a 1% probability of faulty routes, the overall probability of failure quickly becomes too close to 100%. There is therefore no way to deploy edge without fixing the Internet first.
This is very easy to understand in China. But it is also true in Europe and USA (maybe not yet in Japan).
re6st routing provides one solution to that. re6st is available in China (license: 中华人民共和国增值电信业务经营许可证:沪A1-20140091). Nexedi has the right to provide global low latency high resiliency IPv6 network for IoT.
In addition to re6st, we use buffering to that we do not lose data sent by edge nodes (gateways or sensors) in case of application server failure for example:
Both re6st and fluentd are used in all IoT deployments done by Nexedi and based on SlapOS.
Linuxboot
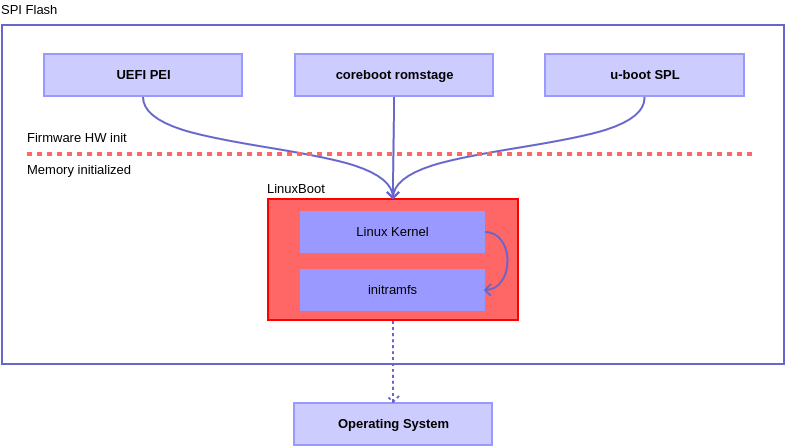
LinuxBoot is a firmware for modern servers that replaces specific firmware functionality like the UEFI DXE phase with a Linux kernel and runtime. Why? Improves boot reliability by replacing lightly-tested firmware drivers with hardened Linux drivers. Improves boot time by removing unnecessary code. Typically makes boot 20 times faster. Allows customization of the initrd runtime to support site-specific needs (both device drivers as well as custom executables). Proven approach for almost 20 years in military, consumer electronics, and supercomputing systems – wherever reliability and performance are paramount.
Future
The future of SlapOS depends on SlapOS main users as well as on community contributions.
Time Sensitive Hybrid Networks
- TSN Gateway
- TS Ethernet
- TS Wifi
- TS LTE (based on FLOSS)
- TS NR (based on FLOSS)
The main development of SlapOS NMS is to support time sensitive networks that are used for industrial automation.
Industrial automation provides some market opportunities that are absent currently in commercial LTE/NR networks. We therefore plan to support at the core of SlapOS the concept of time sensitive network (TSN), starting with Ethernet and Wifi. Once we can use an LTE stack that is at the same time licensed as Free Software and reliable, we will extend the TSN concept to LTE/NR networks.
Nexedi already has some TSN core technology developed 15 years ago and already deployed in Germany.
We are now looking for research partners interested in this direction. Please feel free to contact me.
References
- https://slapos.nexedi.com/ contains the documentation and tutorials, especially some architecture introduction
- https://www.erp5.com/P-OSTV-Tutorial.Nms.Learning.Track NMS tutorial
You can find more articles related to SlapOS:
- https://slapos.nexedi.com/ contains the documentation and tutorials, especially some architecture introduction
- https://www.erp5.com/P-OSTV-Tutorial.Nms.Learning.Track contains NMS tutorial
- https://www.ctocio.com/tech/computing/16071.html explains how SlapOS solves problems similar to those solved by Plan9 but using "services" rather than "files".
- https://www.cio.com/article/2417512/servers/vifib-wants-you-to-host-cloud-computing-at-home.html was the first press article when we started to deploy "cloud servers at home" which can be considered as one type of edge computing
Thank You
- Nexedi SA
- 147 Rue du Ballon
- 59110 La Madeleine
- France
- +33629024425